This is the Part 3 of my series of tutorials about the math behind Support Vector Machine.
If you did not read the previous articles, you might want to start the serie at the beginning by reading this article: an overview of Support Vector Machine.
What is this article about?
The main focus of this article is to show you the reasoning allowing us to select the optimal hyperplane.
Here is a quick summary of what we will see:
- How can we find the optimal hyperplane ?
- How do we calculate the distance between two hyperplanes ?
- What is the SVM optimization problem ?
How to find the optimal hyperplane ?
At the end of Part 2 we computed the distance  between a point
between a point  and a hyperplane. We then computed the margin which was equal to
and a hyperplane. We then computed the margin which was equal to  .
.
However, even if it did quite a good job at separating the data it was not the optimal hyperplane.
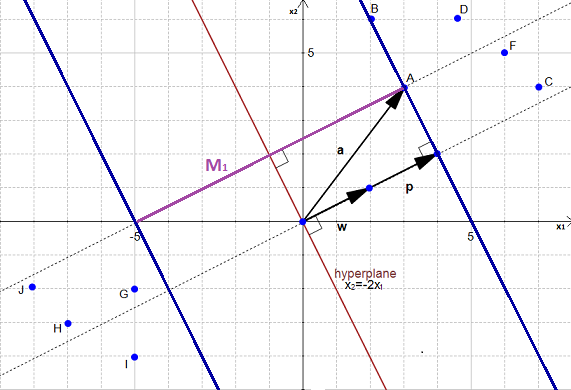
As we saw in Part 1, the optimal hyperplane is the one which maximizes the margin of the training data.
In Figure 1, we can see that the margin  , delimited by the two blue lines, is not the biggest margin separating perfectly the data. The biggest margin is the margin
, delimited by the two blue lines, is not the biggest margin separating perfectly the data. The biggest margin is the margin  shown in Figure 2 below.
shown in Figure 2 below.
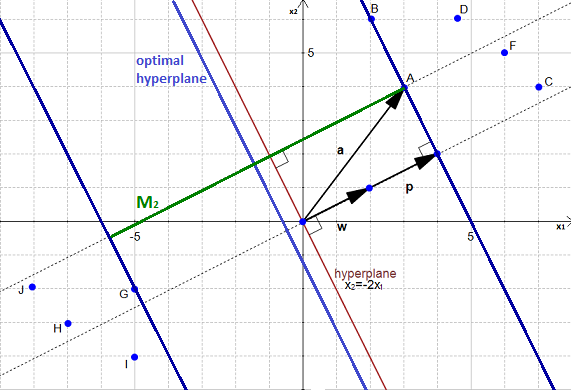
You can also see the optimal hyperplane on Figure 2. It is slightly on the left of our initial hyperplane. How did I find it ? I simply traced a line crossing in its middle.
Right now you should have the feeling that hyperplanes and margins are closely related. And you would be right!
If I have an hyperplane I can compute its margin with respect to some data point. If I have a margin delimited by two hyperplanes (the dark blue lines in Figure 2), I can find a third hyperplane passing right in the middle of the margin.
Finding the biggest margin, is the same thing as finding the optimal hyperplane.
How can we find the biggest margin ?
It is rather simple:
- You have a dataset
- select two hyperplanes which separate the data with no points between them
- maximize their distance (the margin)
The region bounded by the two hyperplanes will be the biggest possible margin.
If it is so simple why does everybody have so much pain understanding SVM ?
It is because as always the simplicity requires some abstraction and mathematical terminology to be well understood.
So we will now go through this recipe step by step:
Step 1: You have a dataset  and you want to classify it
and you want to classify it
Most of the time your data will be composed of  vectors
vectors  .
.
Each will also be associated with a value  indicating if the element belongs to the class (+1) or not (-1).
indicating if the element belongs to the class (+1) or not (-1).
Note that can only have two possible values -1 or +1.
Moreover, most of the time, for instance when you do text classification, your vector ends up having a lot of dimensions. We can say that is a  -dimensional vector if it has dimensions.
-dimensional vector if it has dimensions.
So your dataset is the set of couples of element 
The more formal definition of an initial dataset in set theory is :

Step 2: You need to select two hyperplanes separating the data with no points between them
Finding two hyperplanes separating some data is easy when you have a pencil and a paper. But with some -dimensional data it becomes more difficult because you can't draw it.
Moreover, even if your data is only 2-dimensional it might not be possible to find a separating hyperplane !
You can only do that if your data is linearly separable
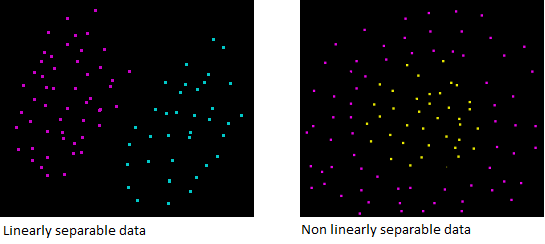
So let's assume that our dataset IS linearly separable. We now want to find two hyperplanes with no points between them, but we don't have a way to visualize them.
What do we know about hyperplanes that could help us ?
Taking another look at the hyperplane equation
We saw previously, that the equation of a hyperplane can be written

However, in the Wikipedia article about Support Vector Machine it is said that :
Any hyperplane can be written as the set of points
satisfying
.
First, we recognize another notation for the dot product, the article uses  instead of
instead of  .
.
You might wonder... Where does the  comes from ? Is our previous definition incorrect ?
comes from ? Is our previous definition incorrect ?
Not quite. Once again it is a question of notation. In our definition the vectors  and have three dimensions, while in the Wikipedia definition they have two dimensions:
and have three dimensions, while in the Wikipedia definition they have two dimensions:
Given two 3-dimensional vectors  and
and 


Given two 2-dimensional vectors  and
and 


Now if we add  on both side of the equation
on both side of the equation  we got :
we got :


For the rest of this article we will use 2-dimensional vectors (as in equation (2)).
Given a hyperplane  separating the dataset and satisfying:
separating the dataset and satisfying:

We can select two others hyperplanes  and
and  which also separate the data and have the following equations :
which also separate the data and have the following equations :

and

so that is equidistant from and .
However, here the variable  is not necessary. So we can set
is not necessary. So we can set  to simplify the problem.
to simplify the problem.

and

Now we want to be sure that they have no points between them.
We won't select any hyperplane, we will only select those who meet the two following constraints:
For each vector  either :
either :

or

Understanding the constraints
On the following figures, all red points have the class  and all blue points have the class
and all blue points have the class  .
.
So let's look at Figure 4 below and consider the point . It is red so it has the class and we need to verify it does not violate the constraint 
When  we see that the point is on the hyperplane so
we see that the point is on the hyperplane so  and the constraint is respected. The same applies for
and the constraint is respected. The same applies for  .
.
When  we see that the point is above the hyperplane so
we see that the point is above the hyperplane so  and the constraint is respected. The same applies for
and the constraint is respected. The same applies for  ,
,  ,
,  and
and  .
.
With an analogous reasoning you should find that the second constraint is respected for the class .
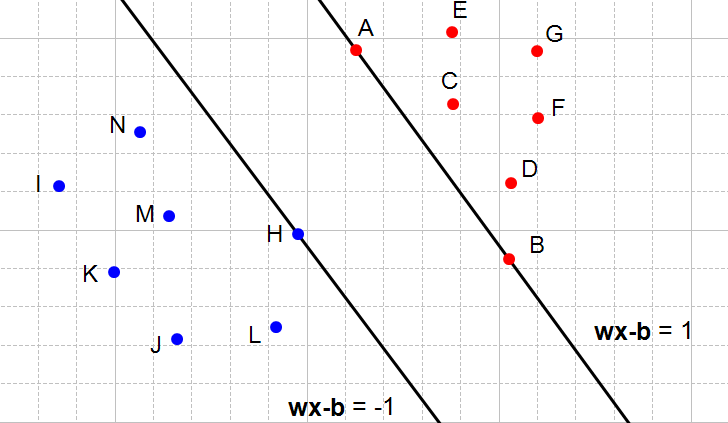
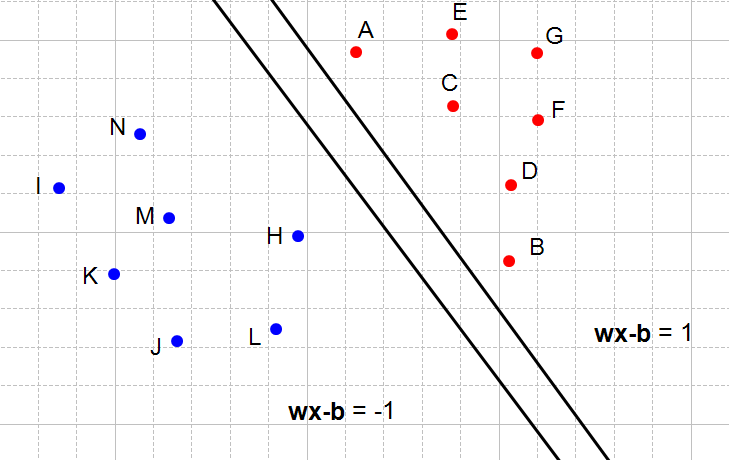
On Figure 5, we see another couple of hyperplanes respecting the constraints:
And now we will examine cases where the constraints are not respected:
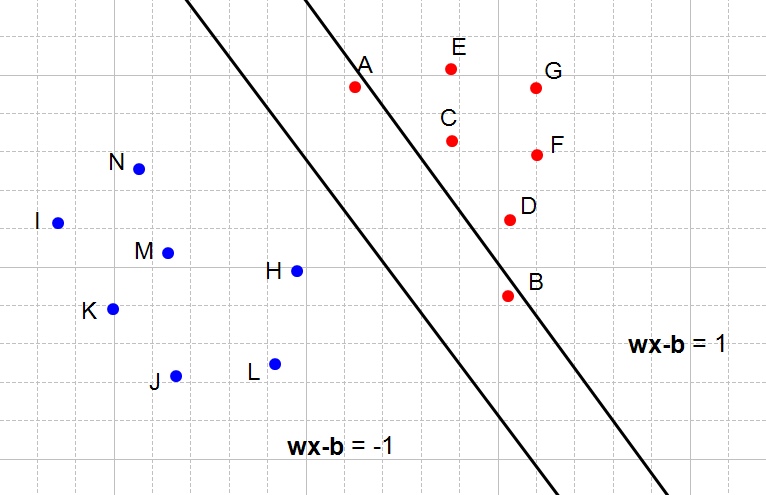
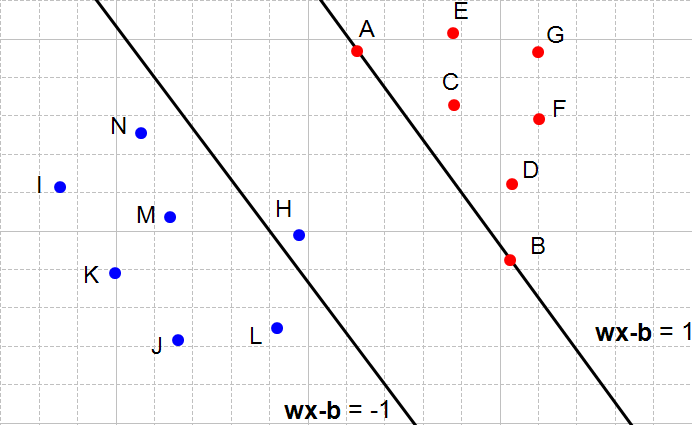
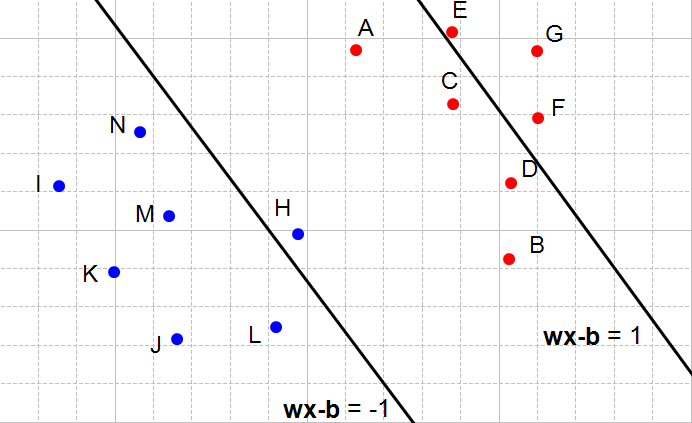
What does it means when a constraint is not respected ? It means that we cannot select these two hyperplanes. You can see that every time the constraints are not satisfied (Figure 6, 7 and 8) there are points between the two hyperplanes.
By defining these constraints, we found a way to reach our initial goal of selecting two hyperplanes without points between them. And it works not only in our examples but also in -dimensions !
Combining both constraints
In mathematics, people like things to be expressed concisely.
Equations (4) and (5) can be combined into a single constraint:
We start with equation (5)


And multiply both sides by (which is always -1 in this equation)

Which means equation (5) can also be written:

In equation (4), as  it doesn't change the sign of the inequation.
it doesn't change the sign of the inequation.

We combine equations (6) and (7) :

We now have a unique constraint (equation 8) instead of two (equations 4 and 5) , but they are mathematically equivalent. So their effect is the same (there will be no points between the two hyperplanes).
Step 3: Maximize the distance between the two hyperplanes
This is probably be the hardest part of the problem. But don't worry, I will explain everything along the way.
a) What is the distance between our two hyperplanes ?
Before trying to maximize the distance between the two hyperplane, we will first ask ourselves: how do we compute it ?
Let:
 be the hyperplane having the equation
be the hyperplane having the equation 
 be the hyperplane having the equation
be the hyperplane having the equation 
 be a point in the hyperplane .
be a point in the hyperplane .
We will call  the perpendicular distance from to the hyperplane . By definition, is what we are used to call the margin.
the perpendicular distance from to the hyperplane . By definition, is what we are used to call the margin.
As is in , is the distance between hyperplanes and .
We will now try to find the value of .
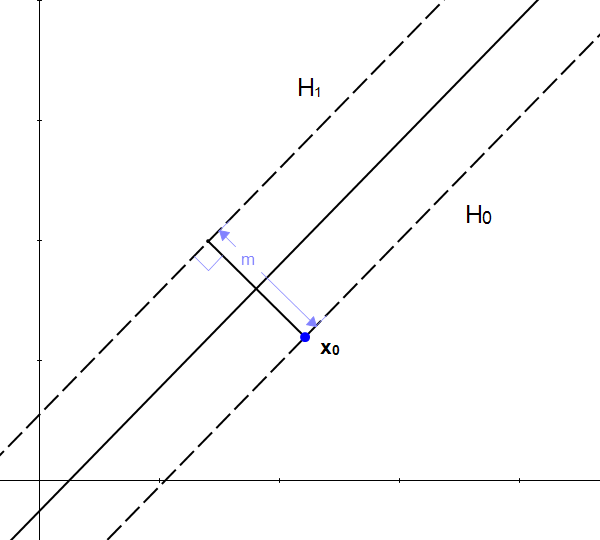
You might be tempted to think that if we add to we will get another point, and this point will be on the other hyperplane !
But it does not work, because is a scalar, and is a vector and adding a scalar with a vector is not possible. However, we know that adding two vectors is possible, so if we transform into a vector we will be able to do an addition.
We can find the set of all points which are at a distance from . It can be represented as a circle :
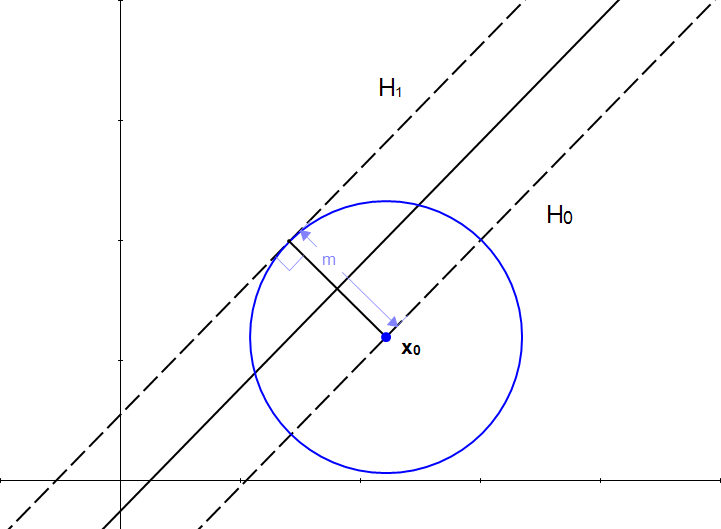
Looking at the picture, the necessity of a vector become clear. With just the length we don't have one crucial information : the direction. (recall from Part 2 that a vector has a magnitude and a direction).
We can't add a scalar to a vector, but we know if we multiply a scalar with a vector we will get another vector.
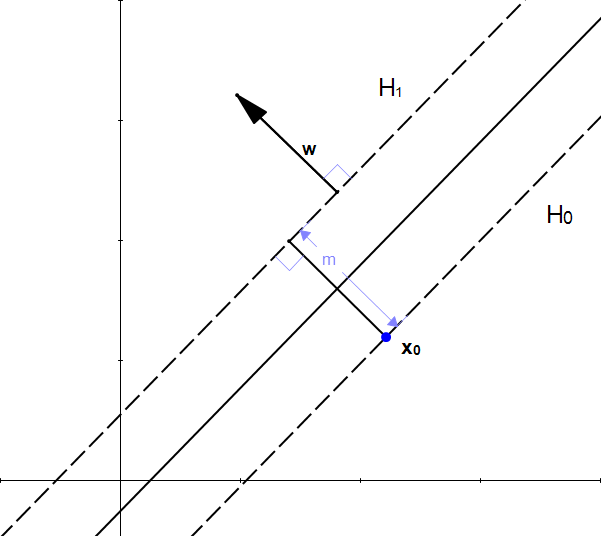
From our initial statement, we want this vector:
- to have a magnitude of
- to be perpendicular to the hyperplane
Fortunately, we already know a vector perpendicular to , that is  (because
(because  )
)
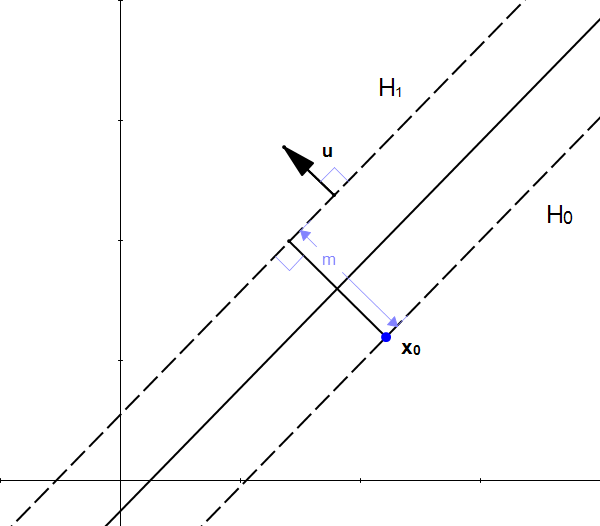
Let's define  the unit vector of . As it is a unit vector
the unit vector of . As it is a unit vector  and it has the same direction as so it is also perpendicular to the hyperplane.
and it has the same direction as so it is also perpendicular to the hyperplane.
If we multiply  by we get the vector
by we get the vector  and :
and :

 is perpendicular to (because it has the same direction as )
is perpendicular to (because it has the same direction as )
From these properties we can see that is the vector we were looking for.
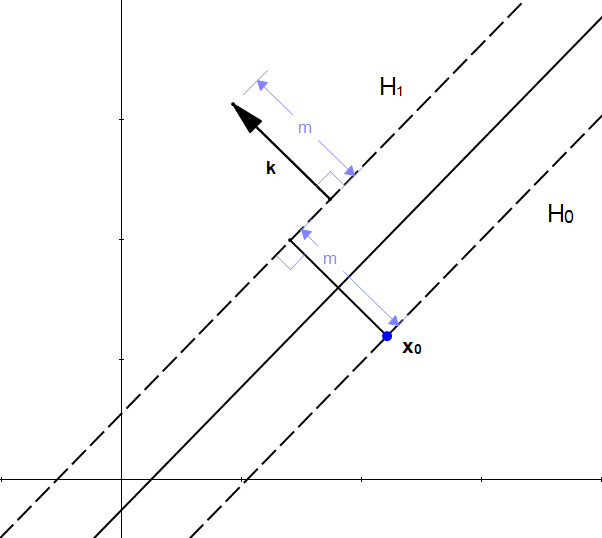

We did it ! We transformed our scalar into a vector which we can use to perform an addition with the vector .
If we start from the point and add  we find that the point
we find that the point  is in the hyperplane as shown on Figure 14.
is in the hyperplane as shown on Figure 14.
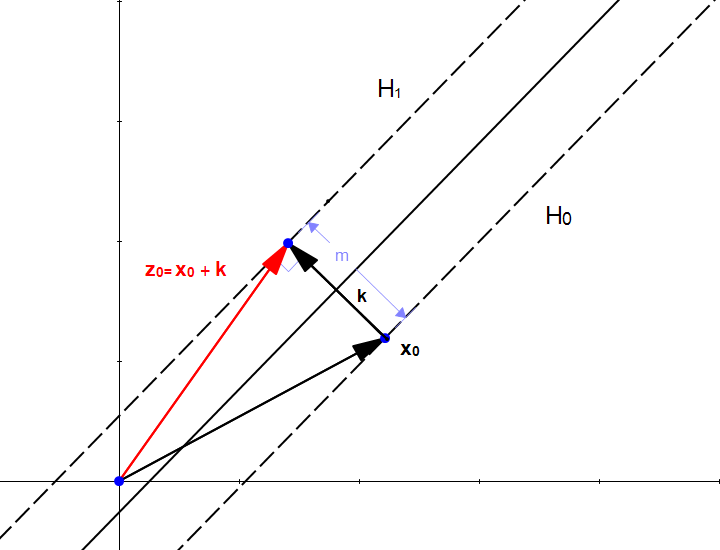
The fact that  is in means that
is in means that

We can replace by  because that is how we constructed it.
because that is how we constructed it.

We can now replace using equation 

We now expand equation 

The dot product of a vector with itself is the square of its norm so :



As is in then 



This is it ! We found a way to compute .
b) How to maximize the distance between our two hyperplanes
We now have a formula to compute the margin:

The only variable we can change in this formula is the norm of .
Let's try to give it different values:
When  then
then 
When  then
then 
When  then
then 
One can easily see that the bigger the norm is, the smaller the margin become.
Maximizing the margin is the same thing as minimizing the norm of
Our goal is to maximize the margin. Among all possible hyperplanes meeting the constraints, we will choose the hyperplane with the smallest  because it is the one which will have the biggest margin.
because it is the one which will have the biggest margin.
This give us the following optimization problem:
Minimize in ( )
)
subject to 
(for any  )
)
Solving this problem is like solving and equation. Once we have solved it, we will have found the couple () for which is the smallest possible and the constraints we fixed are met. Which means we will have the equation of the optimal hyperplane !
Conclusion
We discovered that finding the optimal hyperplane requires us to solve an optimization problem. Optimization problems are themselves somewhat tricky. And you need more background information to be able to solve them. So we will go step by step. Let us discover unconstrained minimization problems in Part 4! Thanks for reading.
I am passionate about machine learning and Support Vector Machine. I like to explain things simply to share my knowledge with people from around the world.