This is the Part 6 of my series of tutorials about the math behind Support Vector Machines.
Today we will learn about duality, optimization problems and Lagrange multipliers.
If you did not read the previous articles, you might want to start the serie at the beginning by reading this article: an overview of Support Vector Machine.
Duality
In mathematical optimization theory, duality means that optimization problems may be viewed from either of two perspectives, the primal problem or the dual problem (the duality principle). The solution to the dual problem provides a lower bound to the solution of the primal (minimization) problem. (Wikipedia)
The concept of duality is pretty simple to understand if you know what a lower bound is.
What is a lower bound?
If you have a partially ordered set  (a set having comparable elements, where the relation "less than or equal" can be used), the lower bound is an element of which is less than or equal to every element of
(a set having comparable elements, where the relation "less than or equal" can be used), the lower bound is an element of which is less than or equal to every element of  .
.
To be less abstract. If you pick a real number (from the partially ordered set  ) and it is less than or equal to every element of a subset of , then you can call this element a lower bound.
) and it is less than or equal to every element of a subset of , then you can call this element a lower bound.
Example:
Let us consider the subset of :

- Because 1 is less than or equal to 2, 4 ,8 and 12, I can say that 1 is a lower bound of S.
- The same is true for -3 for instance.
- And even if it is in S we can also call 2 a lower bound of S.
Moreover, because 2 is larger than any other lower bounds, we can give it a special name, we call it the infimum (or greatest lower bound).
So in our example, you can find an infinity of lower bound, but there is only one infimum.
Note: The same logic apply with the relation "greater than or equal" and we have the concept of upper-bound and supremum.
Coming back to duality
Now that we know what a lower bound is, what do we understand about the definition of duality? Well, this definition means that if you have a minimization problem, you can also see it as a maximization problem. And when you find the maximum of this problem, it will be a lower bound to the solution of the minimization problem, i.e. it will always be less than or equal to the minimum of the minimization problem.
Why do we care about duality?
It turns out that sometimes, solving the dual problem is simpler than solving the primal problem. From what we saw about lower bounds, we can see that for some problems solving the dual problem gives us the same result as solving the primal problem! But when?
Let us look at a visual illustration.
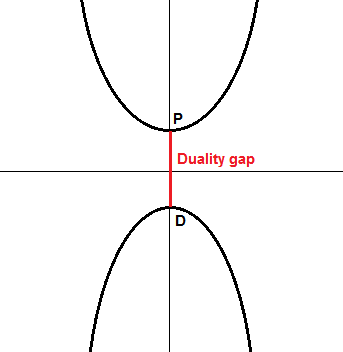
In the schema above, imagine that in our primal problem, we are trying to minimize the function at the top of the graph. Its minimum is the point  . If we search for a dual function, we could end up with the one at the bottom of the graph, whose maximum is the point
. If we search for a dual function, we could end up with the one at the bottom of the graph, whose maximum is the point  . In this case, we clearly see that is a lower bound. We defined the value
. In this case, we clearly see that is a lower bound. We defined the value  and call it the duality gap. In this example,
and call it the duality gap. In this example,  and we say that weak duality holds.
and we say that weak duality holds.
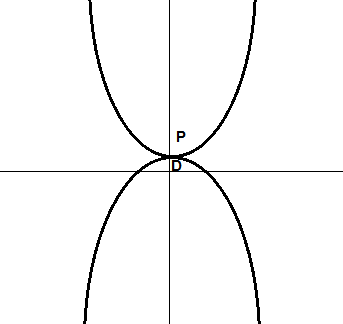
In the schema below, we see that  , there is no duality gap, and we say that strong duality holds.
, there is no duality gap, and we say that strong duality holds.
Optimization problems with constraints
Notation
An optimization problem is typically written:

This notation is called the standard form. You should know that there are others notations as well.
In this notation,  is called the objective function (it is also sometimes called the cost function). By changing
is called the objective function (it is also sometimes called the cost function). By changing  (the optimization variable) we wish to find a value
(the optimization variable) we wish to find a value  for which is at its minimum.
for which is at its minimum.
There is also  functions
functions  which define equality constraints and
which define equality constraints and  functions
functions  which define inequality constraints.
which define inequality constraints.
The value we find MUST respect these constraints!
What does it mean to respect the constraints?
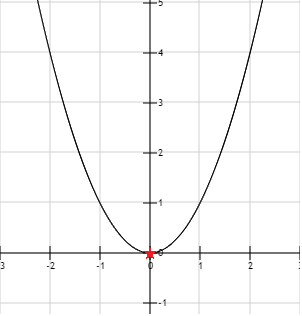
Imagine you try to solve the following optimization problem:

There is no constraint, so finding the minimum is easy, the function  is 0 when
is 0 when  . This is shown with a red star on the graph below:
. This is shown with a red star on the graph below:
Equality constraints
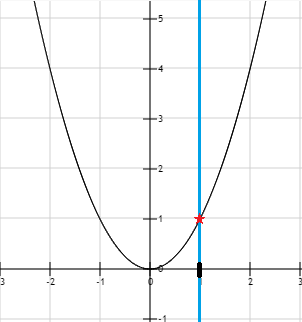
However, what if we try to add an equality constraint? For instance, we want to find the minimum, but we must ensure that  . It means we need to solve this optimization problem:
. It means we need to solve this optimization problem:

This time, when we try  we see that the function returns its minimum, however, we cannot say this is the solution of our optimization problem. Indeed, the constraint is violated. In this example, our only choice is to use and this is the solution.
we see that the function returns its minimum, however, we cannot say this is the solution of our optimization problem. Indeed, the constraint is violated. In this example, our only choice is to use and this is the solution.
Looking at this example, you might feel like equality constraints are useless. This is not the case because most of the time optimization problems are performed in more than one dimension. So you could try to minimize a function  with only an equality constraint on $x$ for instance.
with only an equality constraint on $x$ for instance.
Inequality constraint
What if we now use an inequality constraint? It gives us a problem of the form:

This time, we can try more value of . For instance,  respects the constraint, so it could potentially be a solution to the problem. In the end, we find that the function has once again its minimum at under the constraint.
respects the constraint, so it could potentially be a solution to the problem. In the end, we find that the function has once again its minimum at under the constraint.
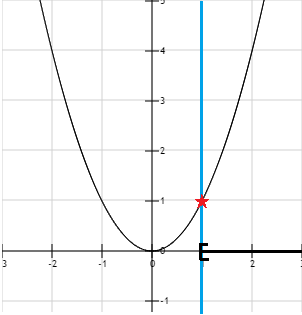
On the graph above, the feasible region is shown in black bold it is a set of values of we are authorized to use. It is also called, the feasible set.
In mathematical notation we can write it:

 is the set of values of for which the constraints are satisfied.
is the set of values of for which the constraints are satisfied.
Combining constraints
It is possible to add several constraints to an optimization problem. Here is an example with two inequality constraints and its visual representation:

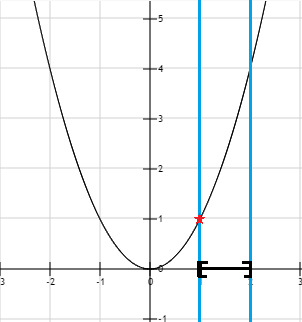
Note that we can also mix equality and inequality constraints together. The only restriction is that if we use contradictory constraints, we can end up with a problem which does not have a feasible set:

Indeed, for a constraint to be respected, it must be true. When there is several constraints, they all must be true. In the example above, it is impossible for to equal 1 and to be less than zero at the same time.
For a function  with one equality constraint
with one equality constraint  and one inequality constraint
and one inequality constraint  the feasible set is :
the feasible set is :

What is the solution of an optimization problem?
The optimal value of the optimization problem:
is:

Basically, it says in mathematical notation that the optimal value is the infimum of  with all the constraints respected.
with all the constraints respected.
How do we find the solution to an optimization problem with constraints?
We will be using the Lagrange Multipliers. It is a method invented by the Italian mathematician, Joseph-Louis Lagrange around 1806.

Lagrange multipliers
As often, we can find a pretty clear definition on Wikipedia:
In mathematical optimization, the method of Lagrange multipliers is a strategy for finding the local maxima and minima of a function subject to equality constraints. (Wikipedia)
The critical thing to note from this definition is that the method of Lagrange multipliers only works with equality constraints. So we can use it to solve some optimization problems: those having one or several equality constraints.
But don't worry, the Lagrange multipliers will be the basis used for solving problems with inequality constraints as well, so it is worth understanding this simpler case 🙂
Before explaining what the idea behind Lagrange multipliers is, let us refresh our memory about contour lines.
Contour lines
It is important to understand contour lines to appreciate better Lagrange multipliers.
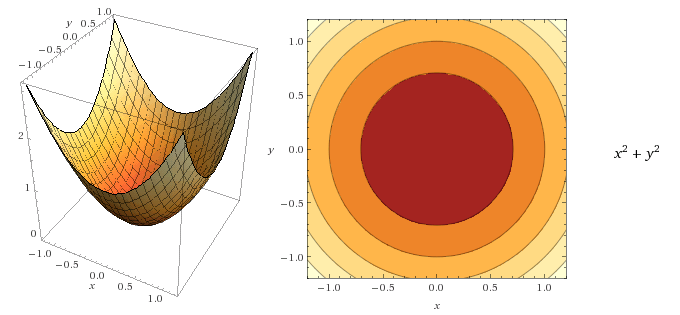
A contour plot is a way to visualize a three-dimensional function into two dimensions.
For instance, the picture below shows the function  displayed in 3D (left) and with a contour plot (right):
displayed in 3D (left) and with a contour plot (right):
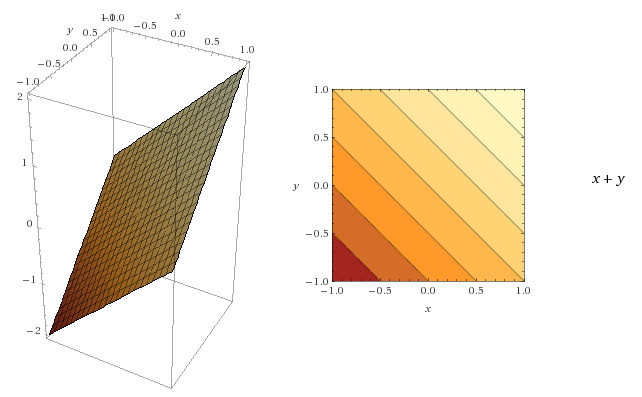
Key concepts regarding contour lines:
- for each point on a line, the function returns the same value
- the darker the area is, the smallest the value of the function is
You can see the last point illustrated in the two figures below. Even if they have the same lines, the change of color allows us to draw a 3D picture of the function in our mind.
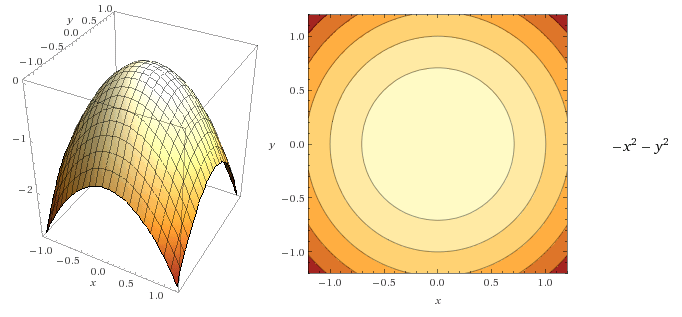
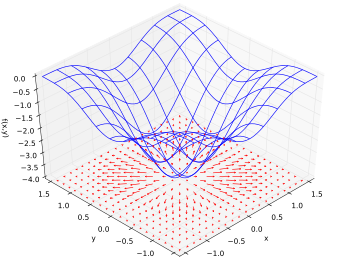
Moreover, the gradient of a function can be visualized as a vector field, with the arrow pointing in the direction where the function is increasing:
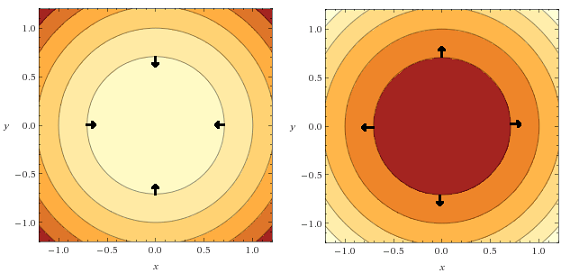
It turns out we can easily draw gradient vectors on a contour plot:
- they are perpendicular to a contour line
- they should point in the direction where the function is increasing
Here is a representation on two contours plots:
Back to Lagrangian multipliers
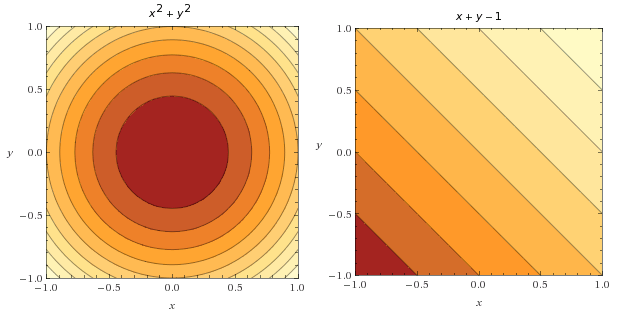
Let us consider the following optimization problem:

The objective function and the constraint function  can be visualized as contour in the figure below:
can be visualized as contour in the figure below:
It is interesting to note that we can combine both contour plot to visualize how the two functions behave on one plot. Below you can see the constraint function depicted by blue lines.
Also, I draw some gradient vectors of the objective function (in black) and some gradient vectors of the constraint function (in white).
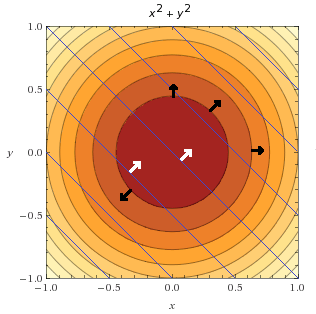
However, we are not interested in the whole constraint function. We are only interested in points where the constraint is satisfied, i.e.  .
.
It means that we want points where:



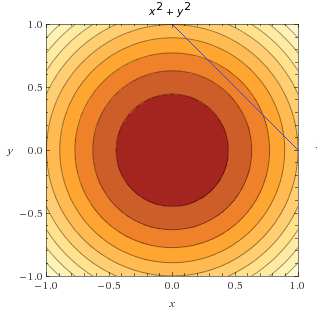
In the graph below we plot the line on top of the objective function. We saw earlier that this line is also called the feasible set.
What did Lagrange find? He found that the minimum of under the constraint is obtained when their gradients point in the same direction. Let us look at how we can find a similar conclusion.
In the figure below, we can see the point where the objective function and the feasible set are tangent. I also added some objective function gradient vectors in black and some constraint gradient vectors in white.
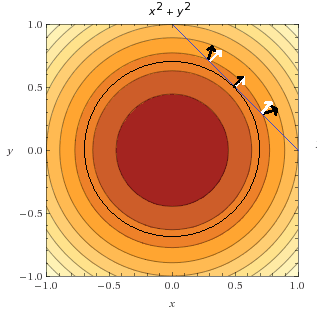
We can see that the is only one point where two vectors point in the same direction: it is the minimum of the objective function, under the constraint.
Imagine you put your finger on the first point with arrows at the top of the figure. Here you evaluate the objective function, and you find out it returns some value  . Now, you wish to know if there is a smaller value. You must stay on the blue line, or the constraint will be violated. So you can either go to the left or the right.
. Now, you wish to know if there is a smaller value. You must stay on the blue line, or the constraint will be violated. So you can either go to the left or the right.
You would like to go left, but then you see that the gradient of the objective function is pointing towards the left (remember it is always pointing towards greater values) so it might not be a good idea. To be sure, you try and go to the left. You find out that the objective function returns  , so it is increasing which is not okay. Going to the right, this time, the objective function returns
, so it is increasing which is not okay. Going to the right, this time, the objective function returns  , it is good you are going in the correct direction. So you continue like that until you reach the center point where the two arrows are parallel. But then, once you move a little bit you find out that the objective function is increasing again. As you can not move right or left anymore without increasing the objective function, you conclude this point is the minimum.
, it is good you are going in the correct direction. So you continue like that until you reach the center point where the two arrows are parallel. But then, once you move a little bit you find out that the objective function is increasing again. As you can not move right or left anymore without increasing the objective function, you conclude this point is the minimum.
How does it translate mathematically?
Lagrange told us that to find the minimum of a constrained function, we need to look or points were  .
.
But what is  and where does it come from?
and where does it come from?
It is what we call a Lagrange multiplier. Indeed, even if the two gradient vectors point in the same direction, they might not have the same length, so there must be some factor allowing to transform one in the other.
Note that this formula does not require the gradients to have the same direction (multiplying by a negative number will change the direction), but only to be parallel. It is because it can be used to find both maximum and minimum at the same time (see Example 1 of this article if you want to see how).
How do we find points for which ?
Note that, is equivalent to:

To make things a little easier, we notice that if we define a function:
 then its gradient is:
then its gradient is:

This function  is called the Lagrangian, and solving for the gradient of the Lagrangian (solving
is called the Lagrangian, and solving for the gradient of the Lagrangian (solving  ) means finding the points where the gradient of and
) means finding the points where the gradient of and  are parallels.
are parallels.
Let us solve this example using the Lagrange multiplier method!
Remember, the problem we wish to solve is:
Step 1: We introduce the Lagrangian function
and its gradient is :
Step 2: We solve for its gradient
We solve :
which means solving the following system of equations:


By multiplying the second equation by -1 and adding the first and second equation we get:

so:

We replace  by in the third equation:
by in the third equation:




We replace by  in the first equation:
in the first equation:



We have found a solution : ,  and
and
We conclude that the minimum of under the contraint is obtained for , .
Let us verify if it makes sense with our graphical analysis on the graph below:
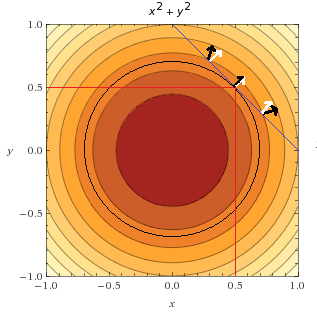
We can see that indeed the point  is on the feasible set (the blue line) and it is the one we identified earlier.
is on the feasible set (the blue line) and it is the one we identified earlier.
Conclusion
In this article, we learned an important concept in optimization: duality. Moreover, we discovered that an optimization problem can have equality and inequality constraints. Eventually, we learned what Lagrange multipliers are and how we can use them to solve an optimization problem with one equality constraint.
If you wish to learn more about Lagrange multipliers in the context of SVM, you can read this very good paper showing how to use them with more equality constraints and with inequality constraints.
When will next part be ready?
There is no next part, but instead I wrote a free e-book about Support Vector Machines. That's your next step if you wish to learn more about SVM!
I am passionate about machine learning and Support Vector Machine. I like to explain things simply to share my knowledge with people from around the world.