Understand how data is represented
For text classification, you often begin with some text you want to classify. For instance, you have quotes and wants to find the quotes about love. Or you have emails and you want to separate spam from legitimate emails.
SVM is a supervised-learning algorithm. It means you will need to manually label some data with what you think is the correct choice. Then you train a SVM model with it. Eventually you can use it to predict unlabeled data.
In order to train a SVM model for text classification, you will need to prepare your data :
- Label the data
- Generate a vocabulary
- Create a document-term matrix.
If you don't have any data yet, you can download one of the available datasets provided for free by the community.
However, you might be surprised by what you will find inside the files:

We want to classify text, but there is only numbers in this file!
A (very) simple dataset for text classification
To understand better how data is represented, I will give you a simple example.
We will try to classify some text about the weather using a support vector machine.
Our goal is to predict if the text is about a sunny or a rainy weather.
To simplify more, each sentence is written with these two words: sunny or rainy.

For each line, we write
- +1 if we think it should be classified as "sunny"
- -1 if we think it should be classified as "rainy".

Then we will look at each word in our dataset, and generate a vocabulary.
We just write each word in alphabetical order.

Eventually, for each sentence, we create a document-term matrix.
We begin the line with the class of the sentence (+1 or -1).
Then we write the index of the word in our vocabulary. For the word sunny it is 2.
We add a colon, and then the number of time the word appears in the sentence.
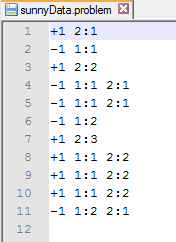
As you can see, we now have a dataset which looks like the example dataset found earlier.